
Mining, oil and gas, and chemical manufacturing companies haven’t yet started to exploit AI, but they can close the gap by applying lessons from other industries.
Artificial Intelligence (AI) solutions have established a strong record of unlocking value across a range of sectors, but continuous process industries such as mining, oil and gas production, and chemical manufacturing have been slower to embrace the technology. The good news is that the relative lack of adoption means AI still offers significant untapped value—if companies take the steps necessary to implement it. By applying the lessons that have worked in other heavy industries, companies can generate gains of 15% or more in efficiency, throughput, reduced waste, and other metrics.
Based on our experience working with several process-industry clients, capturing value through AI requires a three-part solution: collecting the right data, making that data available and accessible, and revamping the company culture to embrace new ways of working. These technologies are now time-tested and constantly improving. Companies can either capitalize on them or cede the advantages of AI to the competition.
Challenges Are Now Outweighed by Recent Advances in AI
There are several reasons why continuous process industrial players have not yet implemented AI. One is that complex processes depend on physical relationships across a wide range of variables, making these processes difficult to model and improve through analytics. Data is often scarce, as many organizations rely on experienced operators who use intuition to handle changing conditions in a given facility. The data that does exist may be of low quality or isolated to individual pieces of equipment, rather than integrated across the entire process.
At the same time, the very nature of these processes makes them prime candidates to improve through analytics. The scientific relationships between process inputs and outcomes guarantee that a specific intervention will impact results—for better or worse—in ways that can be quantified and tracked over time. In addition, the continuous nature of these processes (as opposed to batch processes with a clear beginning and end) enables modeling, rapid testing, and improvement. These advantages are in stark contrast to many other areas, such as marketing, that lack physical cause-and-effect relationships and yet have benefited dramatically from AI.
In the past five years, technological and computational breakthroughs have improved AI to the point where it is no longer an unproven, experimental technology. For example, Bayesian analytics allows companies to overcome scarce data, using probability to make inferences about causality. Machine learning algorithms enable continuous improvements to models over time—particularly relevant for process industries, given the continuous stream of data. Cheap cloud computing resources empower complex optimization algorithms to be solved in minutes rather than days, enabling real-time interventions. Industry 4.0 lets companies embed sensors throughout most continuous processes, creating a large and mostly untapped resource for advanced algorithms.
Many process industries are now at a tipping point. Within five years, advanced machine learning and optimization algorithms will proliferate, giving a clear advantage to technology leaders among process industries.
In sum, the challenges are notable but outweighed by recent advances in AI, and many process industries are now at a tipping point. Within five years, advanced machine learning and optimization algorithms will proliferate, giving a clear advantage to technology leaders among process industries—and leaving laggards further behind.
A Three-Part Strategy for Success
Companies typically progress through a series of stages as they become more mature in AI implementation, though some stages can be leapfrogged. (See the exhibit.) They start with visualizations of one or two processes, producing descriptive statistics and displays. From there, they can begin applying basic AI to a small number of use cases with readily available data, ideally where the fastest gains are possible. As companies build institutional capabilities, they can begin implementing real-time AI to support operators, and then gradually give the algorithms more control over operations. The final stage is closed-loop AI, with operators intervening only in outlier situations.
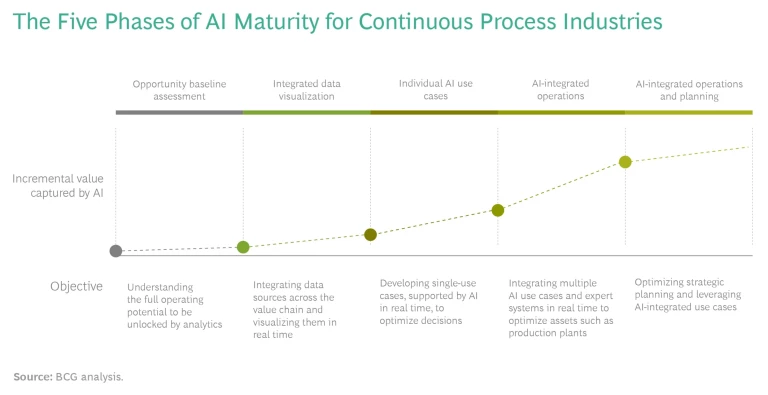
The earlier stages of this evolution are possible using ad hoc approaches based on whatever data is readily available. But to develop real-time applications, companies need a solid data strategy. Developing this strategy requires asking yourself three key questions.
Are you collecting the right data?
Industrial companies often have significant data on hand, but little that they can reliably use. Accordingly, the first challenge is to make sure you’re collecting information on the right factors of a given process, at the right level of accuracy, and constructed in the correct sequence along the entire process. Relevant factors include process KPIs, exogenous variables such as raw material characteristics and control levers.
Data accuracy is critical as well, but there is a potential tradeoff between accuracy and timeliness. For example, readings of specific variables can take place through either online sensors that report data automatically or lab measurements. Generally speaking, lab measurements have both higher accuracy and lower frequency than online sensors, but they are also more labor-intensive. For model calibration, which is performed offline, accuracy should be prioritized. For real-time decision making, online sensors are usually the best option.
In addition, continuous processes present the challenge of sequence and time lags between points in the process. Changes made upstream won’t generate measurable results until that material works its way downstream, making it challenging to link inputs to outcomes. Facilities can use advanced statistical methods to correlate changes at one point in the process to subsequent differences in outcomes.
For example, a base metals mine operator in Latin America developed several analytics models to guide mill operations, but it did not have good data on ore content as it entered the mill from the stockpile. Consequently, the analytics models were not as effective as anticipated. To solve this problem, the company started tracking ore more accurately, through GPS data collected from shovels and trucks as well as RFID data collected between crusher, stockpile, and grinding lines. Armed with richer data, the company was better equipped to predict incoming ore characteristics for its analytics models.
Is the data accessible and available to the right people?
Once you have the right data-collection plan in place, the next priority is making sure the data can be used by the right people at the right time to improve process performance. As with data collection, there are significant challenges to overcome in areas such as maintenance, storage, and retention.
For example, some facilities may have bespoke machines and sensors that record data at the machine itself but don’t integrate it into a broader database. In other cases, sensors get added or removed over time, either “freezing” historical data that can’t be used for future optimization or aggregating new data without any history. Even worse, machines, parts, and entire process layouts may change over time, all of which compound data challenges. Because continuous processes contain many cross-variable interactions, upgrading one machine may change the behavior of another, ultimately affecting the outcome.
To address these challenges, it’s important to create a robust data management pipeline. This process needs to archive snapshots of sensor data over time and automatically record when sensors are recalibrated, added, or removed, as well as when machines or layouts are changed.
It’s important to create a robust data management pipeline, archiving snapshots of sensor data over time and automatically recording when sensors are recalibrated, added, or removed, as well as when machines or layouts are changed.
Optimally, the data should be centralized in the cloud, so that companies have a single point of collection and a straightforward means for operators to access the data. If network connectivity is a challenge, on-site storage might be necessary. In either case, there is a need for a data engineering team with a clear vision of the role data plays in the operation of the plant, and this, in turn, is built on the foundation of an overall data strategy for the company.
A North American copper mine wanted to improve the way it separated valuable metal from waste, through a process known as flotation. To gain real-time feedback on performance, the mill installed X-ray on-stream analyzers (OSAs) to measure copper concentration at the end of the process. The OSA vendor provided an algorithm that converted readouts to copper concentrations, but the company realized that the vendor’s model wasn’t accurate. To rectify this, the company reverted to the raw X-ray data and developed its own internal model. This resulted in new, more accurate real-time measurements—and better overall performance in the process.
Do you have the right culture and operating procedures in place?
Even with strong data, AI transformations in continuous processes won’t succeed without a shift in culture—operators and teams that are willing to use the solutions, change their behaviors, and work in new ways.
It may seem that continuous process industries are engineering-oriented and should have a culture that is a natural fit for advanced analytics. Yet continuous process plants sometimes have a decentralized operational structure, giving local teams latitude in operational decision-making. In addition, engineers and process operators are experts who are rightfully skeptical of algorithms replacing them. Last, typical engineering methods place a premium on deterministic and highly precise views of physical systems—in contrast to the probabilistic approaches of modern machine learning techniques.
Management must communicate that AI-generated recommendations are meant as one factor in human decision-making, rather than a replacement for it.
To boost acceptance, operators should be allowed to accept or reject AI-generated recommendations, especially early on, until the algorithm begins to yield credible results. Management must communicate that the recommendations are meant as one factor in human decision-making, rather than a replacement for it. This communication should directly address operators’ concerns about being replaced. And the tools themselves should be explained using language that emphasizes simplicity and transparency over raw algorithmic sophistication.
Perhaps the most challenging shift is to embrace a more probabilistic world view and a willingness to experiment (provided all safety concerns are met). Probabilistic models will be sometimes right and sometimes wrong—but overall, more right than wrong. These models cannot be perfected before they are adopted in the plant. It is significantly more expedient to get the model into operation and allow it to iteratively improve. Therefore, leadership needs to make clear that operators will not be punished for adopting safe but imperfect models that on average improve performance even though there are hiccups now and then.
On the whole, AI applications have tremendous upside for continuous process industries. The challenges listed here should not be understated, but concrete and feasible solutions exist for each of them. We are finally at a point in the development of advanced technologies where these solutions can be implemented by a skilled team with a high expectation of success. The critical step is to invest in the people, technologies, and cultural messaging required to make the transformation possible.





