
Companies that combine site reliability engineering with AI and machine learning can overcome the increased complexity and instability caused by outmoded, inefficient IT systems.
Many IT systems are outmoded and inefficient, often impeding the overall financial performance and productivity of an organization. And as wide-scale digitization drives expanded use of existing IT systems—particularly in new processes, apps, and programs—and multiple systems integrations generate inconsistencies in implementation, the situation is likely to get worse. Yet despite the increased complexity and instability that results in legacy IT systems and diverse IT architectures, many companies make the mistake of underinvesting in technology. They wrongly consider IT to be independent from an organization’s strategic business goals and thus view IT budgets as low-hanging fruit when costs need to be reduced. Over time, of course, this only puts IT operations further behind the curve.
To overcome these issues, companies can adopt an approach that combines two essential elements of modern IT management:
- Site reliability engineering (SRE) uses flexible, modular software along with software engineering techniques, including automation, to manage systems and automate operational tasks. With SRE, large IT applications and systems that have historically been handled—often manually—by operations teams are instead broken down into microservices and managed separately, usually by software itself without human involvement. SRE makes daily IT operations faster, less prone to failure, and more scalable.
- Artificial Intelligence for IT Operations (AIOps) leverages AI engines to autonomously handle proactive troubleshooting, upgrades, modernization, and improvements in service performance.
This approach is successful because it addresses the root causes of IT system instability, breakdowns, and lagging performance, thus enhancing the quality of service. When companies adopt this approach, IT can realize its true potential and add significant value to the organization through five crucial characteristics:
- Fast time to market, implementing changes in systems, services, and products in days and hours instead of months
- Resilience, relying on intelligent, proactive, and automated recovery, repairs, and maintenance
- Cost-efficiency, automating tasks that add little value
- Security, providing end-to-end cyber resilience
- Business process improvement, responding quickly with apps, programs, and quality-of-service levels that directly serve both internal user and external customer expectations as well as improve business performance and operations
The Benefits of an SRE Framework
The consequences of outmoded and inefficient IT systems are easy to see. They include an increasing number of service outages and successful cyber attacks as well as glitches in establishing reliable remote-working arrangements and access to critical files and information during the current pandemic. In one financial institution, for example, we observed a 170% increase in fraud attempts at the peak of the virus outbreak. In addition, weak results from KPIs that measure customer satisfaction can be also blamed on IT hiccups that disrupt seamless customer interactions.
Aging systems have also caused computer failures. In February 2021, in what was called an “operational error,” the US Federal Reserve System, which banks use to transfer money to one another, went down for a number of hours, affecting billions of dollars in transactions. And about one-third of European financial technology companies have faced scrutiny from regulators because of concerns about the reliability of computer systems at their partner banks.
SRE, which ultimately focuses on reducing technology complexity, costs, inefficiency, and unreliability, can help organizations overcome these challenges and continue to grow and perform at a proficient level.
SRE can help organizations overcome challenges and continue to grow and perform at a proficient level.
In our engagements with clients, we have seen numerous instances of decades-old systems supporting ultramodern customer-facing websites. These systems can slow down the activity on a company’s website and across its network, making the customer or internal user’s experience more frustrating and prone to error. They also hog IT maintenance and management resources, generating a cascade of vulnerability in other parts of the IT network. Moreover, legacy IT operations require constant, time-consuming, manual fixes and resets. To implement a program change, for example, a few dozen servers may have to be taken down—but the change will have to be deployed one by one. And then each server will need to be restarted, again in succession, and manually checked to ensure that the change was implemented correctly.
With SRE, however, much of this process could be automated, and individual parts of the network could be continuously monitored so that glitches are caught before they turn into a system-wide issue.
Even greater benefits accrue when SRE is combined with AIOps.
What’s more, even greater benefits accrue when SRE is combined with AIOps. For example, IT operations will have fewer random fires to put out every day, in large part because automation addresses many individual issues as they arise, and this results in lower IT costs. With these gains, IT teams can focus on critical tasks, such as improving strategic collaboration with the business side to better determine which applications to implement and why. They can also focus on upskilling to adopt more modern ways of working and more viable tools for long-term resilience. Equally important, the effectiveness of SRE and AIOps is measured by transparent service level indicators that are based on business service level improvements. And as SRE and AIOps generate real gains, confidence to embark on more innovative digital transformations grows.
Clearly, the SRE approach has many more benefits than traditional IT processes. Nevertheless, adopting it as a framework for the IT operations of the future can be daunting. BCG believes that adoption can be simplified by separating implementation into three individual facets of an overall journey: assessing technology resilience, executing the SRE approach, and improving the system with AIOps. (See the exhibit.)
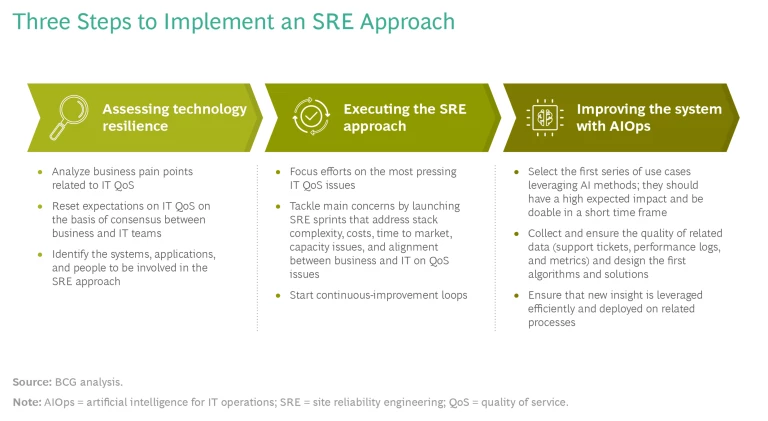
Assessing Technology Resilience
Among the many changes that SRE brings to an organization’s IT operations is the fundamental recognition that SRE is not a siloed IT investment; the business side also plays a significant role in SRE strategy. This is primarily because SRE tools help companies improve business operations through automation, efficiency, and better performance quality while adding value by providing or maintaining digital programs and apps that are essential to the organization’s growth. Consequently, before adopting an SRE approach, business-side teams and IT teams should jointly assess their organization’s technology and make difficult decisions about expectations for its quality of service and performance, the benefits it will provide, and how it will further the company’s strategic goals.
As a result of these discussions, the teams can then draw up a targeted IT operating model with specific goals for each strategic objective. In this assessment, leaders should align on achievable projections for quality of service and other metrics. For instance, a company may strive to decrease the number of downtime incidents by 30%, aim to detect 80% of glitch events in advance, or work to increase traffic due to a new, more streamlined website by 50%. (Trying to improve performance by 100% when a lesser amount would be sufficient can lead to unnecessary investments.) Similar objectives can be established for the cost savings gained by reducing the amount of time it takes to fix problems or to redo work that has already been completed.
In this phase, leaders will have to make more hard choices that will affect company resources, capabilities, governance, and culture. For instance, they will need to identify the technology needed, including platforms, middleware, cybersecurity controls, software, and apps. They will also need to define the roles and responsibilities required to manage this significant IT shift. The revised management structure may include new continuous-learning teams composed of SRE-focused members from business, software development, and IT. Also, recruiting and upskilling plans need to be put in place to add more SRE engineers, AIOps data scientists, and automation specialists.
An organizational investment and governance blueprint to fund, implement, and monitor the performance of future IT operations must also be drawn up. Budgeting and execution projections should closely mirror the scope of SRE goals, which can range from incremental changes that improve resilience to structural overhauls that, for instance, modularize and automate a full set of features within a large-scale application.
Executing the SRE Approach
When the newly drawn up IT resilience operating model—which includes a technology roadmap—is in hand, the company can begin making SRE improvements designed to modernize the IT landscape, streamline software development, and enhance incident monitoring and response. In our experience, the SRE approach can deliver five critical benefits for IT systems and operations. These benefits should be designed to be incremental and continuously improving and should ultimately be rooted as core strategic goals in the organization.
A Reduction in the Complexity of the Technology Stack. The SRE approach evaluates IT architecture from core systems to front ends with the aim of identifying potential single points of failure and eliminating them—for instance, with the help of redundant designs. In addition, avoiding incident spread across the system is a key element of SRE. Known for reducing the blast radius of a component—that is, the negative impact on other parts of the system of a single component breakdown—and for keeping the greatest number of users in operation during a system glitch, this concept can be implemented with more modular architecture designs and circuit breakers.
Furthermore, SRE targets proactive failure detection through mechanisms that constantly check the service levels of all components involved in a critical business process. These mechanisms allow for extremely fine monitoring via advanced probes placed at crucial junctures in the process. For instance, the system might regularly monitor the execution of an underlying task—a customer’s purchase or a financial transaction—and signal when a predefined error rate is reached before it breaks the system. If that error threshold is reached, the task can be automatically switched to another database until the original one is repaired and ready to perform at an acceptable level again.
Lower Platform Costs. SRE can help address several cost levers. The most obvious one involves a core principle of the SRE approach: to significantly reduce the impact of service outages, which swallow up staff resources because IT teams are forced en masse to put out fires rather than work on value-added projects and IT improvements.
Part of the reason that system downtime is trimmed back lies in a much higher degree of automation of IT controls and application deployment, a hallmark of SRE. That, in turn, lessens the costs of operational support to monitor latency and error rates. And automation makes installing new software, fixing program glitches, and upgrading existing applications much more cost-effective. Under current conditions, some IT departments spend more than 50% of their time on manual tasks that could be automated using an SRE blueprint.
Other, less apparent, cost-saving opportunities are equally advantageous. For instance, as SRE simplifies the IT architecture, the number of licenses required decreases, and maintenance costs fall because fewer technology components are needed.
An Acceleration in Time to Market. SRE addresses several IT critical processes, leading to faster time to market for software delivery. Automation, again, plays a key role. Acceleration in design, development, and the speed of implementation can be seen in the faster provisioning of components in different technology environments, more rapid quality assurance testing, improved response time to problems, and greater flexibility.
We observed recently that one company took up to 40 days to install a new server on its network. Of course, the IT staff involved in this process would have liked to accelerate the implementation, but the numerous required handoffs slowed down the effort: The person who prepped the hardware had to pass it along to someone to install the operating system, and that person couldn’t get to it for a few days. Then, someone else had to build the libraries, and another person had to create the applications before the network could even be configured. And at the end, yet more teams had to conduct security and quality testing. In all, ten hours of work took more than a month to complete. By contrast, using an SRE approach supported by so-called DevOps tools that speed up software development, an entire application environment for a website, multiple workstations, and remote devices can be scripted and put online in as little as 20 minutes.
Dramatic shifts in design and deployment help IT teams become more open to taking risks and making changes that substantially improve a company’s IT operations performance.
These kinds of dramatic shifts in design and deployment offer a more profound improvement that is equally valuable to an organization: given that time to market becomes less of an issue, and the company makes significant gains in resilience and reliability, IT teams become more open to taking risks and making changes that can substantially improve a company’s IT operations performance. In other words, the simplicity and efficiency of SRE-based implementations provide a heightened level of confidence that taking other large steps, such as moving a network to the cloud or designing a new application for a new market, will be successful and not unduly burdensome.
Enhanced Capacity of the IT Team. SRE improves the productivity of IT staffers considerably—a testament to the benefits of automation and the overall gains in efficiency and resilience. As manual work involving deployment, troubleshooting, and maintenance is reduced and IT operations components and environments are standardized, technology teams can focus on new projects or improvements with real potential returns.
Part of the explanation for why SRE principles can expand productivity is that they rely on so-called error budget discipline to avoid excess technical debt. This means that because of the acceleration and efficiencies in hardware, network, and software development using the SRE approach, IT teams are more likely to complete all the design and maintenance tasks right from the beginning as part of the process, rather than postpone some issues for the sake of time. Having to return to a long list of remaining items at the end of a project, or failing to completely address user concerns, paves the way for introducing more bugs, mistakes, and delays.
Alignment Between Business and IT on Quality-of-Service and Performance Issues. Traditionally, IT has viewed applications and infrastructure performance from a technical angle, using quantitative metrics, such as uptime or response time, that often fail to provide the full picture. For instance, an e-commerce site may appear to be running without noticeable problems 95% of the time. But a closer look reveals that customers often experience performance issues at critical moments, such as when trying to pay for a product with a credit card. Optimizing performance at these pivotal customer interactions could have more salient impact on the business side of the company than achieving 100% uptime.
To address this disconnect between the priorities of IT and business operations, SRE approaches the issue of quality of service from an end user perspective. Working backwards from the performance expectations related to specific critical business processes, SRE delineates required service level objectives. These objectives, and the metrics that are used to gauge whether they are being met, become the roadmap that all parts of the organization can share to assess technology resilience.
Improving the System with AIOps
Adopting SRE techniques delivers substantial improvements on its own. But as a result of the outsized role of automation in SRE-based IT operations, adding AI and machine learning capabilities—in essence, combining intelligence with automation—provides even better returns. AIOps introduces the extended use of data and advanced analytics into network and applications control and management, arming IT teams with tools to augment operational excellence. In our experience, companies that implement AIOps can reduce their IT support costs by 20% to 30% while increasing user satisfaction throughout the organization and freeing up IT time for more rewarding tasks.
AIOps can be used in many ways in IT operations. For example, it can be deployed to leverage advanced analytics to enhance the management of problem incident support tickets. In this regard, AIOps programs might analyze support tickets for patterns that would indicate emerging systems’ issues before they become a problem. The programs could then route support tickets quickly to the appropriate teams so the nascent problems and their root causes can be addressed. And for many recurring problems, the AI programs could handle the repair without any human intervention.
Using machine learning, AIOps can even jump on an issue before it becomes a major headache—often before a support ticket is written. For example, a machine learning system installed at one particular financial services firm reads through technology infrastructure and applications logs and metrics coming from IT monitoring programs. The system attempts to identify and filter out false-positive alerts and recognize and weigh the importance of the real problems. It then automatically assigns those problems to the right specialists, who may be able to accelerate troubleshooting and prevent the incident from affecting operations. Since this system was installed, incident detection at the firm is up by 85% and application downtime has dropped by 40%.
BCG research has shown that advanced companies that have hired teams with strong data-related skills—including data scientists and data and software engineers—as well as expertise in implementing advanced analytics solutions using AIOps have had some operational success working with IT operations. But many challenges still remain to increase the impact and value of these activities.
For one thing, data scientists are often the ones who choose the specific applications for AIOps models and algorithms. As a result, these decisions are frequently driven by IT team biases and constraints and not prioritized to create value in key areas of the organization or to address the urgent needs of the business environment and its primary strategies. For another, the data scientist teams that are charged with overseeing the AIOps implementations—and are expected to assess results and generate insight for improvements—lack the change management skills required for continuous innovation in IT operations.
To overcome these shortcomings, the best approach is to carefully select a series of AIOps deployments that are urgent but doable in a short period of time. In this process, proof-of-value exercises should be used to establish a roadmap that prioritizes applications. The impact on the performance of IT operations across the organization should be forecast, and KPIs should be developed as metrics. AIOps design and development should occur relatively quickly in order to rapidly produce results, which will demonstrate the value of this approach, and then build on that positive experience for future deployments.
A Raft of Benefits
BCG’s three-phase framework for embracing the SRE approach and enhancing the system with AIOps can help a company improve business process resilience through quality-of-service and performance gains as well as amplify the value of IT operations and improve the bottom line. Of course, the deployment of an IT operations of the future should be an ongoing effort, with frequent changes and improvements. But each step will bring the company closer to reducing recurrent outages, breakdowns, and malicious incidents, such as cyber attacks, while scaling IT operations so that they prioritize critical company strategies quickly and less expensively than before.
Considering the significance of digitization, AI, and other advanced technologies on competitiveness these days, the fact that choosing the SRE path raises expectations for what IT operations can deliver is notable. In time, this approach can compel real value from IT teams that are too often viewed as costs without returns.





